
🤦 Framsteg som DeepSeek är det pessimisterna alltid missar
AI-utvecklingen är på väg in i en vägg, sa pessimisterna. Så dök DeepSeek upp och förstörde deras argument.
Dela artikeln
AI-utvecklingen håller på att sakta ner och närmar sig en vägg, har allt fler hävdat på senare tid. Det påståendet bygger de på att AI-modellerna har blivit bättre genom att tränas på allt mer data men att det inte finns så mycket ny data kvar. De har redan glufsat i sig det mesta på internet, därför kommer de inte kunna bli bättre.
Men hejsan hoppsan så dök DeepSeek upp!
DeepSeek är en ny kinesisk AI-tjänst. Deras modell R1 presterade i nivå med modellerna från Open AI, Google och Meta men kostade avsevärt mindre att träna. Anledningen var att man fått den att träna sig själv, genom att ge den incitament att lära sig. När du lär en hund att göra trick, så får den en godis när den är duktig och gör rätt. På samma sätt får AI:n poäng när den kom fram till rätt svar och även om den resonerade på ett bra sätt för att komma dit. Det kallas förstärkningsinlärning.
Aha!
DeepSeek började med att göra en basmodell på liknande sätt som OpenAI och de andra. Man använder förstärkningsinlärning kombinerat med människor som hjälper den att hitta rätt svar, ger feedback och reder ut kniviga situationer. Men för att lära modellen att resonera, alltså att steg för steg komma fram till ett svar eller lösa ett problem, så tog man bort människorna. Den fick basmodellen, ett gäng frågor som den skulle svara på och sedan själv komma på hur.
Den blir långsamt bättre, men efter ett tag trillar polletten ner. Aha! Vilket är precis vad modellen själv kallar det, ett aha-ögonblick. Den håller på att lösa en ekvation när den plötsligt stannar och säger till sig själv: "Wait, wait. Wait."
Den har insett att den behöver backa och omvärdera sin lösning genom att gå igenom stegen igen. Modellen har själv lärt sig att ifrågasätta sitt eget resonemang och göra justeringar.
Även för utvecklarna är detta ett aha-ögonblick. "Snarare än att uttryckligen lära modellen hur den ska lösa ett problem, ger vi den helt enkelt rätt incitament, och den utvecklar själv avancerade problemlösningsstrategier," skriver de.
Småpengar
Den här modellen kallade de R1 Zero, eftersom människor inte var med och hjälpte den. Den funkade emellertid inte att använda just av människor, eftersom modellens resonemang ofta var svåra att förstå. Så baserat på R1 Zero tog de fram modellen R1, som byggde på Zero men fick en bunt grunddata som hjälp, så den skulle bli mer begriplig för oss köttintelligenser.
Att träna denna modell, R1, gjordes mycket effektivt för bara cirka 60 miljoner kronor. Småpotatis i sammanhanget. Det hade behövts färre och mindre effektiva chips att träna den på, vilket fick Nvidias börskurs att rasa. Nvidia gör flest och bäst AI-chips i världen och tappade 6000 miljarder i börsvärde på en dag. Ouch.
Reaktionen var rätt överdriven. Visserligen var träningen av R1 relativt billig, men då hade inte kostnaderna för basmodellen och R1 Zero räknats in, och inte heller något av de tusentals utvecklingstimmar som föregått träningen av modeller. Trots det var DeepSeek ett klart steg framåt i effektivitet och kreativitet.
Naiva pessimister
Det är just det här som pessimisterna gång på gång missar. Ska man vara snäll kan man säga att de lever i nuet. Deras standardargument är att om vi ska bygga X så kommer det behövs jättemycket av Y – och det finns inte, är otroligt dyrt, omöjligt, etcetera.
Låt oss ta något helt annat som exempel: Kobolt i batterier. Så här argumenterar pessimisterna:
- Kobolt bryts ofta under dåliga villkor.
- Ska vi ha massa elbilar kommer vi behöva enorma mängder kobolt.
- Alltså massa lidande.
- Därför kan/bör vi inte skala upp tillverkningen av elbilar.
Men det är inte så det funkar. Vilket visas av den här grafen. Den visar efterfrågan på kobolt 2019, 2020, 2021 och 2022.
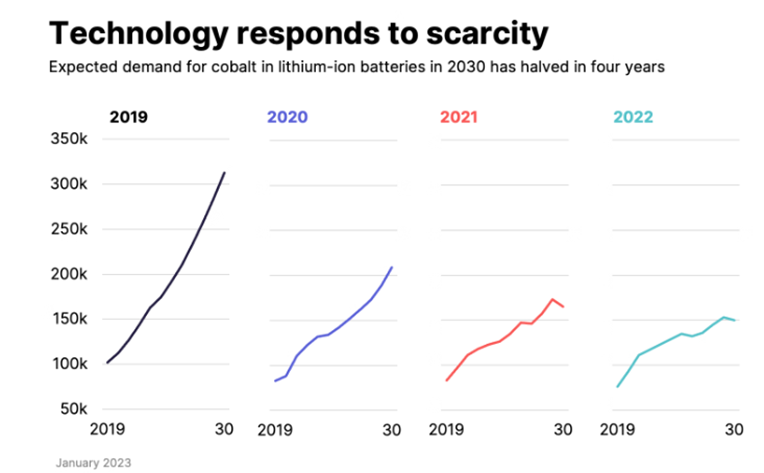
När vi stöter på brister eller problem utvecklar vi alternativ. Gång på gång missar pessimisterna det! Och så kallar de optimister för naiva...
Brist på chips ledde till...
USA har infört exportrestriktioner till Kina på de bästa AI-chippen. Det finns med andra ord inte tillräckligt många och bra chips i Kina för att träna på samma nivå som de amerikanska konkurrenterna. Det tvingade kineserna att tänka nytt – och vips, där hade vi DeepSeek.
Jämför det med Elon Musks xAI. Grok 3 släpptes nyligen och presterar i klass med de bästa modellerna. Dit nådde de med rå kraft. De har byggt ett datacenter med 200 000 av de allra bästa GPU:erna från Nvidia (och slog sannolikt världsrekord i hur snabbt man kan bygga ett så stort datacenter.)
Pessimisterna kan ha rätt i att lågt hängande data börjar ta slut och vi därmed inte kan skapa bättre modeller bara genom mer data. Men dels finns det massor av data som kan tillgängliggöras. Det var något vi i AI-kommissionen tittade på. Exempelvis Kungliga biblioteket har massor av information som inte är digitalt och tillgängligt. När det blir lönsamt och viktigt att tillgängliggöra det, kommer det ske.
Dels kommer vi komma på nya sätt att träna AI-modeller på. DeepSeek har tagit ett första steg i den processen, men många andra kommer att följa.
Så kort vill ingen flyga
När jag lyssnade på en föreläsning med Troed Troedson sa han något träffande:
Vad sa pessimisten som 1903 hörde att människan för första gången flugit ett flygplan en sträcka på 37 meter?
"Så kort vill ingen flyga."
Mathias Sundin
Arge optimisten


